
Leia este blog completo e descubra agora como zerar os custos de manutenção do projeto de segurança da sua instalação.
Solução recomendada
Para reduzir custos recorrentes de manutenção em sistemas de segurança, o caminho mais consistente é especificar e implantar com projeto e integração — priorizando arquitetura, padronização, robustez ambiental e operação remota. Foco em projetos corporativos e infraestrutura crítica (não atendemos residencial).
Em projetos de usinas solares e outras instalações críticas, a segurança costuma ser uma das primeiras preocupações — ou deveria ser. Afinal, ela protege canteiro de obras, equipamentos e ativos valiosos, além de apoiar a continuidade operacional.
O ponto que quase sempre aparece tarde demais é o que vem depois: a manutenção dos equipamentos de segurança. Em ambientes expostos (sol forte, umidade, poeira, vibração, longas distâncias), sistemas com baixa robustez ou arquitetura mal definida acumulam falhas, deslocamentos técnicos e substituições, elevando o custo total de propriedade (TCO).
Este guia mostra como zerar problemas (no sentido de eliminar a recorrência e a previsibilidade baixa) associados a altos custos de manutenção — com foco em decisões técnicas: especificação, arquitetura, componentes, integração, operação 24/7 e métricas como MTBF e MTTR.
Aplicações por setor
Custos altos de manutenção são típicos em operações com grande área, acesso difícil e operação contínua. Dois exemplos onde projeto e integração impactam diretamente o TCO:
Data centers
Operação 24/7, SLA e exigência de evidência elevam a necessidade de padronização, redundância e gestão remota.
Óleo & Gás
Ambiente agressivo e áreas extensas tornam a confiabilidade e a manutenção planejada parte do desenho do sistema.
Nota de retrofit – imagem destacada (OG): criar 1 Featured OG 1200×630 com o título “Como zerar problemas com altos custos de manutenção…” + elementos visuais de CFTV corporativo (câmera, rack, dashboard) e um fundo de usina/infraestrutura crítica. Alt text sugerido: “Redução de TCO e manutenção de sistemas de segurança em usina solar”.
A ilusão do investimento único
Na teoria, os equipamentos de segurança são adquiridos para “resolver o problema” de forma contínua. Na prática, quando o projeto não considera TCO e confiabilidade, surge um padrão recorrente: falhas em cadeia, manutenção corretiva frequente e decisões reativas (trocar peça, reiniciar, remendar).
Em locais remotos, cada falha custa mais do que a peça: deslocamento, janela operacional, interrupção, risco de indisponibilidade e, às vezes, necessidade de replanejar a segurança temporariamente.
Quando as visitas técnicas se tornam recorrentes, elas viram um novo “custo fixo” — e ainda assim não eliminam o risco. Se um sistema falha no momento errado, o que era para ser proteção vira vulnerabilidade: furtos, vandalismo, incidentes operacionais e paradas não programadas.
Esse ciclo costuma seguir um efeito cascata:
- Componentes expostos começam a falhar (energia, conectores, câmeras, sensores, rede);
- Técnicos são mobilizados com frequência (muitas vezes em áreas remotas);
- O atendimento vira “apagar incêndio”, não prevenção;
- A indisponibilidade aumenta justamente quando há degradação do sistema;
- O escopo precisa ser reforçado ou refeito (novos pontos, redundância tardia, troca de marcas/modelos);
- Equipes internas perdem foco do core business para tratar problemas operacionais de segurança.
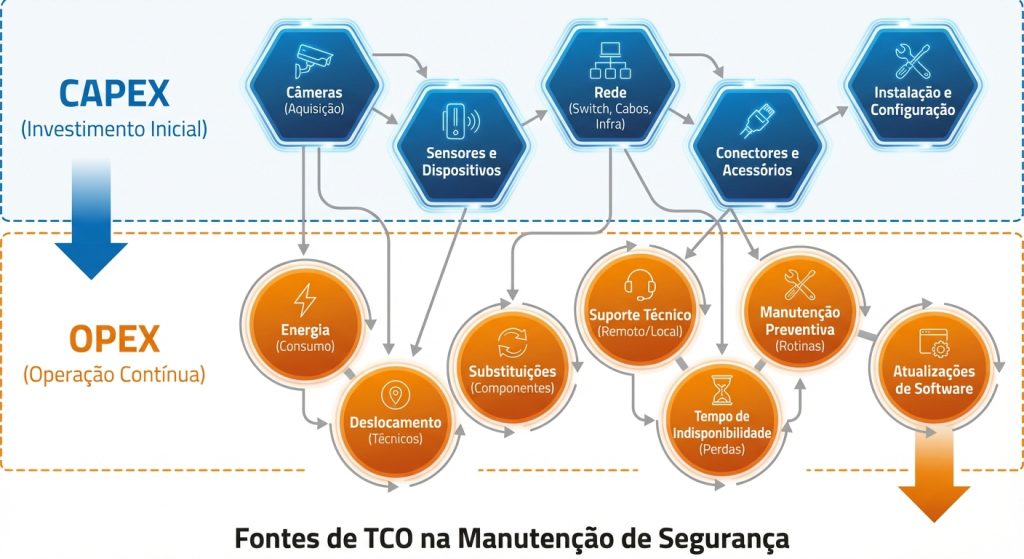
O que é TCO em sistemas de segurança (e por que ele decide o orçamento real)
TCO (Total Cost of Ownership) é o custo total de propriedade ao longo do ciclo de vida do sistema. Em segurança eletrônica, o CAPEX (instalação) é só o começo. O que normalmente “come” orçamento com o tempo é OPEX: manutenção, substituições, suporte, deslocamentos, energia, rede, licenças, tempo de operação e indisponibilidade.
Em termos práticos, reduzir TCO significa diminuir três coisas:
- Quantidade de pontos de falha: menos dispositivos desnecessários, menos emendas, menos “gambiarras” de campo.
- Exposição ambiental: especificar equipamentos e infraestrutura compatíveis com sol, poeira, umidade, vibração e corrosão.
- Tempo para detectar e corrigir falhas (MTTR): operar com monitoramento remoto, logs, alertas e padrões de reposição.
MTBF e MTTR: as duas métricas que explicam a conta de manutenção
Dois indicadores ajudam a tirar “manutenção” do campo do achismo:
- MTBF (Mean Time Between Failures): tempo médio entre falhas. Quanto maior, menor a frequência de corretivas e menor o custo de deslocamento e substituição.
- MTTR (Mean Time To Repair/Restore): tempo médio para reparar/restaurar. Quanto menor, menor a indisponibilidade e menor o risco operacional enquanto o sistema está degradado.
Um sistema pode ter bom MTBF e ainda assim ser caro se o MTTR for alto (por exemplo, quando cada falha exige visita em local remoto sem diagnóstico prévio). Por isso, reduzir manutenção não é só “comprar equipamento melhor”: é projetar para operar.
Por que equipamentos de segurança falham mais em instalações críticas
Em usinas, parques solares, minas, portos e sites extensos, falhas aparecem por causas repetitivas. As mais comuns:
- Ambiente: calor, UV, umidade, poeira, salinidade, vibração e variações térmicas degradam vedação, conectores e cabos.
- Infraestrutura elétrica: surtos, aterramento inadequado, fontes subdimensionadas e ausência de proteção derrubam equipamentos.
- Rede e telecom: enlaces longos, switches sem padrão industrial, conectores expostos e falta de monitoramento causam intermitência.
- Instalação e comissionamento: ângulo inadequado de câmera, fixação frágil, dutos mal executados e emendas sem padrão elevam falhas.
- Arquitetura sem redundância: ponto único de falha em energia, comunicação ou gravação derruba zonas inteiras.
- Operação sem observabilidade: falha só é percebida quando alguém “nota” — e aí o MTTR explode.
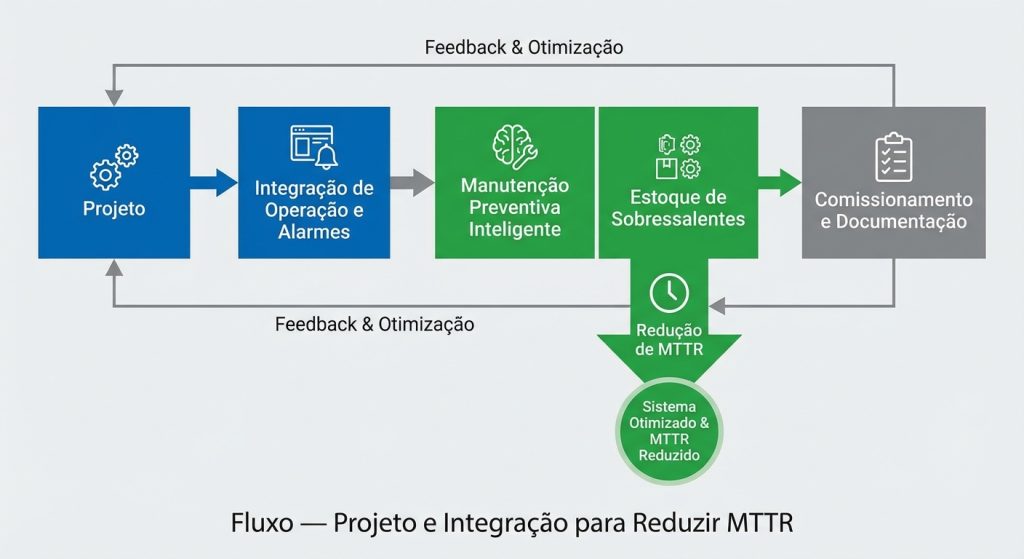
Como reduzir custos de manutenção com projeto e integração (passo a passo)
“Zerar problemas” não é prometer ausência de falhas. É eliminar recorrência e imprevisibilidade com uma abordagem estruturada. Um fluxo técnico típico:
- Auditar o cenário atual: mapear falhas recorrentes por zona (energia, rede, câmera, sensor, servidor) e custos associados (tempo + deslocamento).
- Definir criticidade por área: quais zonas não podem ficar indisponíveis e qual o nível de redundância aceitável.
- Padronizar arquitetura e componentes: reduzir variedade de modelos, fontes, switches, conectores e firmwares.
- Especificar robustez ambiental: selecionar equipamentos e caixas/vedações compatíveis com o ambiente (poeira/umidade/UV/corrosão).
- Projetar energia e proteção: incluir proteção contra surtos, aterramento e redundância onde necessário.
- Projetar rede com observabilidade: monitorar links, PoE, latência, perdas e disponibilidade por porta/zona.
- Integrar operação e alarmes: falhas precisam gerar evento (ex.: câmera offline, storage degradado) com escalonamento.
- Planejar manutenção preventiva mínima e inteligente: limpeza/inspeção por risco e ambiente (não “troca por calendário”).
- Definir estoque de sobressalentes: peças críticas com SLA de reposição, reduzindo MTTR.
- Comissionar e documentar: testes de aceitação, baseline de performance e documentação para futuras intervenções.
Essa abordagem normalmente é entregue em formato de projeto e integração, com responsabilidade clara por arquitetura, instalação, comissionamento e integração com a operação.
CFTV corporativo: onde a manutenção mais “vaza” dinheiro
Em muitos sites, o maior volume de chamados está em CFTV: câmera offline, imagem degradada, lente suja, fonte/PoE instável, storage cheio, firmware inconsistente. Reduzir esses chamados exige olhar para o CFTV como sistema — não como “câmera + gravador”.
Algumas alavancas técnicas de maior impacto:
- Topologia de rede correta: segmentação, QoS, redundância e proteção de enlaces longos.
- Padronização de modelos e firmwares: menos variação = menos incompatibilidades e diagnósticos mais rápidos.
- Instalação robusta: fixação, vedação, conduítes, conectores e proteção contra intempéries.
- Monitoramento de saúde do sistema: câmera offline, perda de frames, storage degradado, CPU/temperatura, falhas de disco.
- Operação por evidência: alarmes de falha e relatórios por zona/turno reduzem “descoberta tardia”.
Para aprofundar esse desenho, vale conectar com CFTV corporativo e com a visão completa de uma empresa de segurança eletrônica para infraestrutura crítica (arquitetura + operação + manutenção planejada).
Comparação técnica: o que aumenta ou reduz custo de manutenção
A tabela abaixo resume escolhas de projeto que, na prática, elevam ou derrubam o TCO ao longo do tempo.
| Decisão de projeto | Impacto típico | Como reduzir manutenção |
|---|---|---|
| Baixa padronização (muitos modelos/marcas) | Mais incompatibilidade, diagnóstico lento, estoque caro | Padronizar linhas, firmwares e conectividade |
| Infraestrutura de rede não industrial | Intermitência e falhas em ambiente agressivo | Especificar rede/caixas/proteções para o ambiente |
| Energia sem proteção e sem redundância | Queima, reinicialização, indisponibilidade | Proteção contra surtos + aterramento + redundância por criticidade |
| Instalação sem vedação e sem padrão | Oxidação, infiltração, cabo degradado | Vedação/caixas corretas + conectores adequados + comissionamento |
| Sem monitoramento de saúde (observabilidade) | Falha descoberta tarde, MTTR alto | Alertas de falha por zona + dashboards + escalonamento |
| Sem estratégia de sobressalentes | Paradas longas aguardando peça | Estoque mínimo por criticidade + SLA de reposição |

O que muda quando manutenção vira estratégia (não reação)
Quando a manutenção é tratada como estratégia de engenharia, os benefícios aparecem em três frentes:
- Menos corretivas e menos deslocamento: redução de chamados repetitivos e troca de peças por falhas previsíveis.
- Mais disponibilidade (uptime): falhas são detectadas cedo e corrigidas antes de virarem indisponibilidade longa.
- Orçamento previsível: OPEX deixa de ser “surpresa” e vira planejamento por criticidade, estoque e contratos.
Como evitamos altos custos com manutenção (princípios técnicos aplicáveis)
Independentemente do fornecedor, existem princípios técnicos que reduzem TCO em segurança eletrônica. Eles são especialmente importantes em sites remotos e infraestrutura crítica:
- Projetar para o ambiente: especificação coerente com poeira, umidade, UV, vibração e corrosão (equipamentos + caixas + conectividade).
- Projetar para operar: monitoramento de saúde do sistema, alarmes de falha, logs e rotinas de atendimento por criticidade.
- Projetar para manter: padronização, documentação, comissionamento e estoque mínimo de sobressalentes para reduzir MTTR.
- Reduzir pontos de falha: arquitetura simplificada, menos “penduricalhos” em campo e integração que evita duplicação.
Em projetos corporativos, esses princípios costumam ser consolidados em um escopo completo de projeto e integração, alinhando engenharia, instalação, comissionamento e operação.
Caso relacionado
Para ver um exemplo de implantação em ambiente com requisitos de disponibilidade e operação crítica, leia o case: UFF Araucária.
Perguntas frequentes (FAQ)
1) O que causa altos custos de manutenção em sistemas de segurança?
Normalmente é a combinação de ambiente agressivo, arquitetura com muitos pontos de falha, baixa padronização, energia/rede sem proteção e ausência de monitoramento de saúde (falha descoberta tarde).
2) O que é TCO em segurança eletrônica?
TCO é o custo total de propriedade ao longo do ciclo de vida: instalação (CAPEX) + operação e manutenção (OPEX), incluindo deslocamentos, reposições, contratos, energia, rede, licenças e indisponibilidade.
3) O que é MTBF e por que ele importa?
MTBF é o tempo médio entre falhas. Quanto maior, menor a frequência de corretivas e menor o custo de deslocamentos e reposições em ambientes críticos.
4) O que é MTTR e como reduzir?
MTTR é o tempo médio para reparar/restaurar. Reduz com diagnóstico remoto, alertas de falha por zona, padronização, documentação e estoque mínimo de peças críticas.
5) Trocar equipamentos resolve o problema de manutenção?
Nem sempre. Se a arquitetura, energia, rede e instalação não forem corrigidas, as falhas tendem a continuar. A redução real de TCO vem de projeto, integração e operação monitorada.
6) Como reduzir chamados de CFTV (câmera offline e imagem degradada)?
Com topologia de rede adequada, proteção elétrica, padronização de firmwares, instalação robusta (vedação/fixação) e monitoramento de saúde (alertas para offline, perda de frames e storage).
7) Qual é o primeiro passo para baixar TCO?
Auditar falhas recorrentes por zona e suas causas (energia, rede, ambiente, instalação), definir criticidade e então reespecificar arquitetura com padronização, observabilidade e plano de sobressalentes.
8) Manutenção preventiva “por calendário” funciona?
Em parte, mas pode ser ineficiente. Em sites críticos, o ideal é combinar inspeções mínimas (limpeza/vedação) com manutenção baseada em condição (alertas, logs e indicadores de degradação).
9) Como evitar que uma falha derrube uma área inteira?
Com redundância por criticidade (energia e rede), segmentação por zonas, eliminação de pontos únicos de falha e comissionamento com testes de aceitação.
10) Por que padronização reduz custo de manutenção?
Porque simplifica firmware, compatibilidade, diagnóstico, estoque de sobressalentes e treinamento da operação. Menos variação normalmente significa MTTR menor.
11) Que documentos ajudam a reduzir MTTR?
As-built, mapa de rede, mapa de zonas, lista padronizada de componentes, baseline de performance, procedimentos de escalonamento e checklists de comissionamento.
12) Onde “projeto e integração” entra nessa conta?
Entra no desenho completo: especificação por ambiente e criticidade, integração (rede/energia/VMS/alertas), comissionamento e rotinas operacionais que transformam falhas em eventos tratáveis — reduzindo OPEX ao longo do tempo.
Leia também
- HSE em instalações críticas: como a IA está transformando essa gestão
- Tecnologias de segurança para proteger trabalhadores em mineradoras
- Como especificar CFTV corporativo para baixo TCO (guia técnico)
Conclusão
Altos custos de manutenção quase nunca são “azar” — normalmente são consequência de arquitetura, especificação e operação que não foram desenhadas para o ambiente e para o ciclo de vida do sistema. Quando você trata manutenção como engenharia (TCO, MTBF, MTTR, padronização e observabilidade), o resultado é previsibilidade, menos corretivas e mais disponibilidade.
Em infraestrutura crítica, cada site tem restrições próprias (ambiente, distância, conectividade, criticidade por zona). Uma abordagem de projeto e integração ajuda a definir arquitetura, padrões e rotinas operacionais para reduzir OPEX sem comprometer segurança e continuidade.
Tags: Projeto e Integração, TCO, MTBF, B2B