
Solução recomendada Para reduzir paradas não programadas causadas por intrusão, vandalismo e incidentes operacionais em usinas de energia, a abordagem mais efetiva é operar por eventos: videomonitoramento 24/7 integrado (VMS + procedimentos/SOP) com segurança perimetral para detecção antecipada e...
Solução recomendada
Para reduzir paradas não programadas causadas por intrusão, vandalismo e incidentes operacionais em usinas de energia, a abordagem mais efetiva é operar por eventos: videomonitoramento 24/7 integrado (VMS + procedimentos/SOP) com segurança perimetral para detecção antecipada e verificação rápida por imagem. Foco em projetos corporativos e infraestrutura crítica (não atendemos residencial).
Paradas não programadas em usinas de energia raramente começam “do nada”. Em muitos casos, existe um encadeamento previsível: um evento inicial (intrusão, sabotagem, falha de um ativo, incêndio/queimada no entorno) evolui para indisponibilidade porque a detecção foi tardia, a verificação foi lenta ou a resposta não seguiu um procedimento claro.
O problema é que, em infraestrutura crítica, a indisponibilidade tem efeito cascata: afeta contratos, reputação, operação do sistema elétrico e, em situações extremas, serviços essenciais. Por isso, reduzir paradas não programadas é uma meta que mistura engenharia, operação e segurança.
Neste guia técnico, você vai entender o que gera paradas não programadas em usinas, como elas se conectam a métricas como MTTR e quais requisitos de segurança ajudam a reduzir o tempo entre “evento” e “ação”.
Nota de retrofit – imagem destacada (OG): criar 1 Featured OG 1200×630 com o título “Paradas não programadas em usinas: como evitar” + ícones de câmera, perímetro e relógio (MTTR). Alt text sugerido: “Videomonitoramento 24/7 para reduzir MTTR e evitar paradas não programadas em usina (infraestrutura crítica)”.
Aplicações por setor
O tema “parada não programada” é transversal em energia, mas fica ainda mais sensível quando há grandes áreas, operação remota e alto custo de deslocamento. Dois exemplos típicos:
Parques solares
Perímetros extensos e pouca presença humana aumentam o risco de eventos virarem indisponibilidade se não houver operação por evento.
Subestações e linhas associadas
Qualquer evento que gere indisponibilidade tem impacto imediato no fornecimento e pressiona MTTR e SLA.
O que são paradas não programadas em usinas de energia?
Parada não programada é qualquer interrupção inesperada de operação (parcial ou total) que reduz disponibilidade e performance da usina fora do cronograma de manutenção ou planejamento operacional. Em infraestrutura crítica, o impacto é medido não só pelo tempo parado, mas pela velocidade de detecção, verificação e recuperação.
- MTTD (Mean Time To Detect): tempo médio para detectar que algo está errado.
- MTTR (Mean Time To Repair/Recover): tempo médio para reparar ou recuperar a operação.
- OPEX e risco: quanto maior o tempo para detectar/verificar, maior a chance do evento escalar (dano, perda de ativo, indisponibilidade).
Em projetos de energia com operação remota, a segurança atua diretamente em MTTD (detecção e evidência) e indiretamente em MTTR (resposta mais assertiva e menos deslocamento “às cegas”).
O custo das paradas não programadas
O custo de uma parada não programada não é um número único. Ele costuma somar:
- Perda de produção/receita: energia não gerada ou não entregue (dependendo do modelo de contrato).
- Custos de O&M emergencial: deslocamento, horas extras, recomissionamento, compra urgente de peças.
- Risco regulatório e reputacional: pressão por continuidade, auditorias e impactos em relacionamento com stakeholders.
- Custos indiretos: aumento de prêmio/condições de seguro, “backlog” de manutenção e indisponibilidade recorrente.
Quando a causa é intrusão (furto/vandalismo), o problema costuma ser duplo: além do dano direto, muitas vezes o restabelecimento depende de inspeção e correção em campo, o que amplia MTTR.
Principais causas de paradas não programadas (o que é prevenível)
Nem toda parada é evitável, mas várias causas são preveníveis ou mitigáveis com projeto correto e operação orientada a eventos. Em usinas, os vetores mais comuns incluem:
- Furtos e roubos: remoção de cabos, componentes e itens de alto valor, com impacto direto em disponibilidade.
- Vandalismo e sabotagem: dano deliberado a infraestrutura, cercas, equipamentos e áreas críticas.
- Baixa visibilidade operacional: eventos passam despercebidos (ou geram ruído), atrasando verificação e resposta.
- Fadiga de alarmes: excesso de falsos positivos faz a equipe “normalizar” alertas e perder o evento real.
- Condições ambientais: poeira, neblina, chuva e baixa iluminação degradam verificação quando o vídeo não está bem especificado.
Note que vários itens acima são, essencialmente, problemas de detecção, verificação e resposta — o que posiciona o videomonitoramento como uma disciplina operacional (não apenas “instalação de câmera”).
Como evitar paradas não programadas com soluções de segurança (passo a passo)
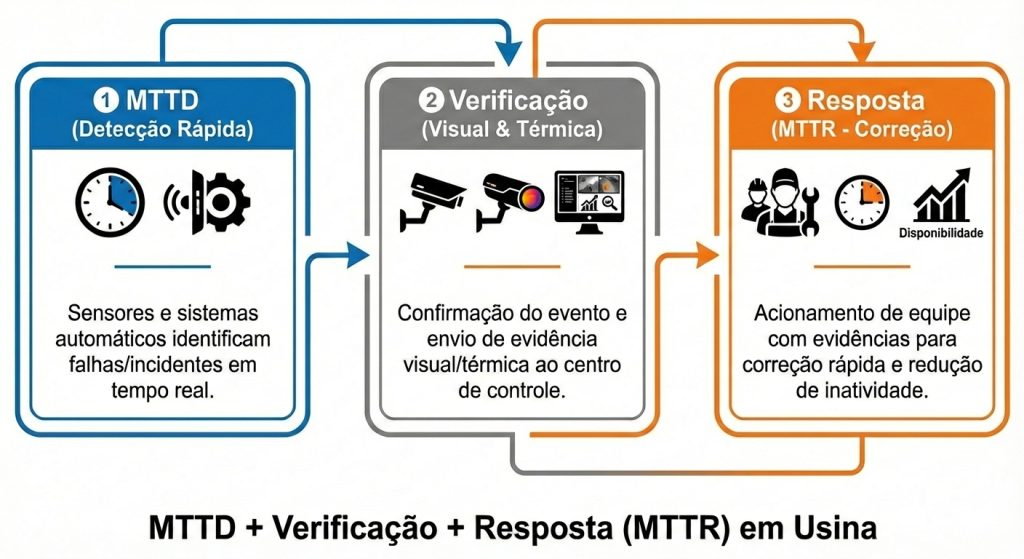
O objetivo técnico aqui é reduzir o tempo entre “evento no campo” e “ação correta”. Um fluxo de referência para usinas de energia:
- Mapeie zonas e criticidade: dividir perímetro e áreas internas em zonas com risco e impacto diferentes (acessos, pontos cegos, áreas remotas, eletrocentro etc.).
- Defina detecção antecipada: em perímetros extensos, a detecção por zona reduz o tempo de busca e evita depender de ronda e “olho na tela”.
- Garanta verificação por evento: alarme abre a cena correta no VMS, grava evidência e reduz o tempo para confirmar se é intrusão, fauna ou ruído.
- Padronize resposta (SOP): procedimento por severidade e por zona (suspeita → confirmação → acionamento), com registro e auditoria.
- Monitore indisponibilidades como risco: câmera offline, link down e falha de energia em ponto crítico precisam virar evento operacional.
- Meça e ajuste: KPIs por zona (taxa de alarmes, tempo de verificação, tempo de resposta) para reduzir ruído e aumentar previsibilidade.
Em termos práticos, isso transforma segurança em um sistema de redução de MTTR (menos deslocamento indevido, mais evidência) e de redução de MTTD (detectar mais cedo e com localização).
Arquitetura recomendada para usinas: perímetro + vídeo + operação
Uma arquitetura consistente para evitar paradas não programadas combina camadas. O desenho muda conforme extensão e topografia, mas a lógica é estável:
- Camada 1 — Segurança perimetral: detectar tentativa de intrusão com indicação de zona/trecho. (Ver segurança perimetral.)
- Camada 2 — Videomonitoramento 24/7: verificação rápida, evidência, rastreabilidade e acionamento. (Ver videomonitoramento.)
- Camada 3 — Operação e integração: VMS, mapas sinóticos (quando aplicável), alarmes, controle de acesso, procedimentos e registros.
Quando essas camadas trabalham juntas, a equipe deixa de “procurar o problema” e passa a atuar com contexto: onde ocorreu, o que está acontecendo e qual ação executar.
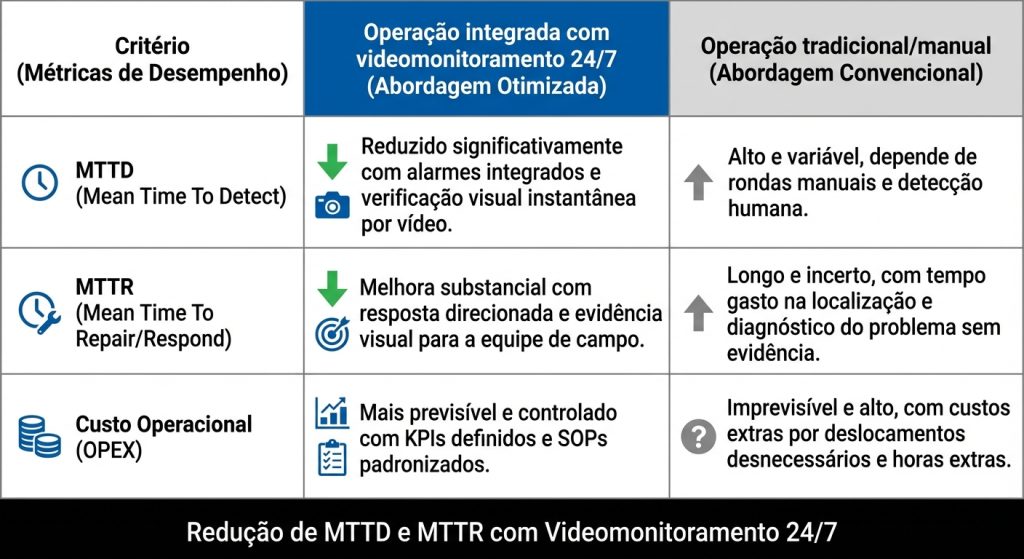
| Critério | Operação por evento (perímetro + vídeo + SOP) | Vídeo isolado / monitoramento manual | Ronda predominante |
|---|---|---|---|
| Coverage | Escala por zonas e integração; reduz pontos cegos quando bem projetado | Depende de densidade de câmeras e atenção humana | Limitada por rota, turno e acesso |
| Falsos alarmes | Reduz com calibração + verificação por evento | Tende a crescer com cenas instáveis e baixa visibilidade | Menos alarmística, porém detecção tardia |
| MTTD | Baixo (evento dispara verificação) | Variável (depende do operador) | Alto (depende de passagem da ronda) |
| MTTR | Melhora com evidência e resposta direcionada | Variável; deslocamentos indevidos são comuns | Alto; pouco contexto e alto tempo de deslocamento |
| Custo operacional | Mais previsível e mensurável por KPI | OPEX tende a subir com “olho na tela” | OPEX alto em horas-homem |
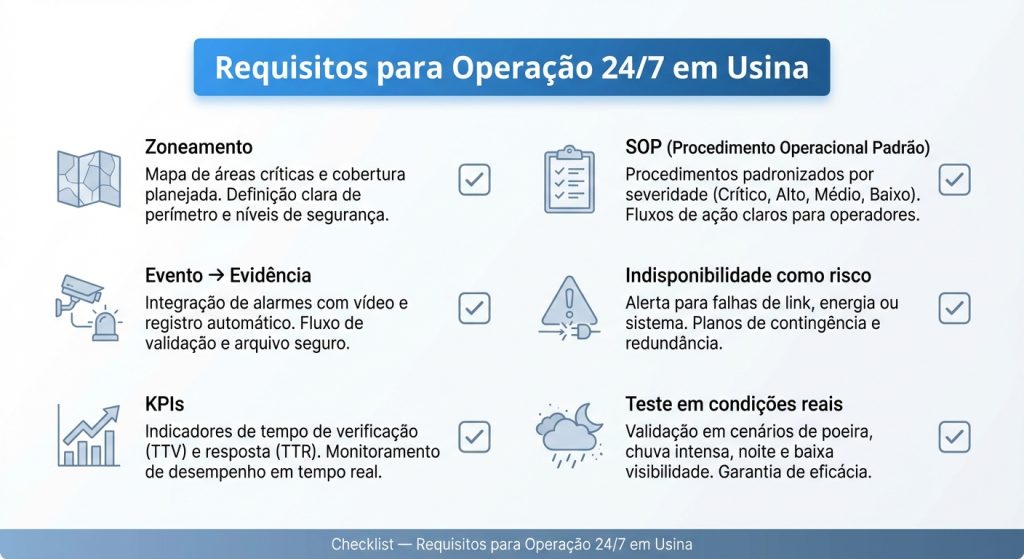
Checklist técnico para reduzir MTTR em operações remotas
Se o objetivo é diminuir paradas não programadas, o retrofit deve sair do “equipamento” e entrar no “processo”. Use o checklist abaixo em projetos novos ou melhorias:
- Zoneamento: perímetro e áreas internas com criticidade definida e cobertura planejada por zona.
- Evento → evidência: alarme abre câmera correta no VMS, grava e registra ocorrência (workflow).
- KPIs: tempo de verificação, tempo de resposta, alarmes por zona, indisponibilidade de links/câmeras.
- SOP: procedimento por severidade, com escalonamento e registro auditável.
- Indisponibilidade como risco: câmera offline e falha de link/energia em ponto crítico devem gerar ação.
- Teste em condições reais: dia/noite, poeira, chuva, neblina e períodos de baixa visibilidade.
Caso relacionado
Para ver um exemplo de operação em infraestrutura de energia com exigência de continuidade, leia o case: Complexo Eólico Seridó.
Leia também
- Furtos e roubos em usinas solares: como garantir a proteção da sua instalação
- Alarmes falsos: um dos maiores desafios da segurança perimetral — como evitar
- Tecnologias mais utilizadas na segurança perimetral de infraestruturas críticas
Conclusão
Evitar paradas não programadas em usinas de energia exige reduzir o tempo entre “evento” e “ação”. Em operações remotas, isso passa por detecção por zona, verificação rápida e resposta padronizada. Quando o videomonitoramento 24/7 é integrado a um processo (VMS + KPIs + SOP) e conectado à segurança perimetral, a operação tende a ganhar previsibilidade e reduzir pressão sobre MTTR.
Como cada usina tem acessos, topografia e criticidade diferentes, uma avaliação técnica do site ajuda a definir zoneamento, integrações e requisitos de operação dentro de uma estratégia corporativa de segurança eletrônica.
Tags: Operação 24/7, MTTR, Energia