
Veja como o MTBF pode moldar o sucesso de projetos de segurança.
Solução recomendada
Se a meta é reduzir falhas, visitas de manutenção e indisponibilidade em sites críticos, priorize uma abordagem de segurança eletrônica para infraestrutura crítica com engenharia de confiabilidade (MTBF/MTTR), padronização e operação orientada a eventos. Foco em projetos corporativos e infraestrutura crítica (não atendemos residencial).
Em infraestrutura crítica, “segurança eletrônica” não é só instalar equipamentos. É manter disponibilidade ao longo de anos em ambientes hostis (calor, poeira, vibração, umidade, corrosão), com operação 24/7 e exigência de evidência. Nesse cenário, MTBF deixa de ser um termo técnico e vira um fator direto de TCO (custo total de propriedade).
Escolher equipamentos com alto MTBF reduz a frequência de falhas e a necessidade de intervenções corretivas. Mas, para evitar decisões erradas, é fundamental entender o que o MTBF realmente mede, como comparar especificações e como transformar esse indicador em requisitos de projeto, integração e operação.
Neste guia, você verá o que é MTBF, como ele se relaciona com disponibilidade e custo operacional, quais armadilhas existem nas fichas técnicas e como especificar um sistema de segurança eletrônica pensando no ciclo de vida — especialmente em sites como subestações e outras operações críticas.
Aplicações por setor
MTBF alto é mais relevante quando há operação 24/7, acesso difícil e tolerância mínima à indisponibilidade. Dois exemplos típicos:
Subestações
Alta criticidade, ambientes expostos e necessidade de evidência e operação contínua.
Data centers
SLA, operação 24/7 e baixa tolerância a falhas em vídeo, rede e gravação.
Nota de retrofit – imagem destacada (OG): criar 1 Featured OG 1200×630 com o título “Por que escolher equipamentos com alto MTBF…” + ícones de confiabilidade (gráfico/engrenagem) e um fundo de subestação. Alt text sugerido: “MTBF e confiabilidade em segurança eletrônica em subestação”.
O que é MTBF
MTBF (Mean Time Between Failures) é o tempo médio entre falhas de um item reparável. Ele não é uma “garantia de vida útil” e não significa que o equipamento vai operar exatamente por aquele período sem falhar. MTBF é uma métrica estatística usada para estimar a frequência de falhas em operação, normalmente sob condições e suposições específicas.
- MTBF descreve frequência de falha, não durabilidade absoluta. Um MTBF alto sugere menor taxa de falhas ao longo do tempo.
- MTBF depende de condições de uso. Temperatura, umidade, vibração, poeira e qualidade de energia/rede podem reduzir a confiabilidade real.
- MTBF é mais útil quando comparado com MTTR. Disponibilidade depende de “quanto falha” (MTBF) e “quanto demora para restaurar” (MTTR).
- MTBF deve ser interpretado com o método e o contexto. Fabricantes podem calcular de formas diferentes (modelagem, testes, campo), o que afeta comparabilidade.
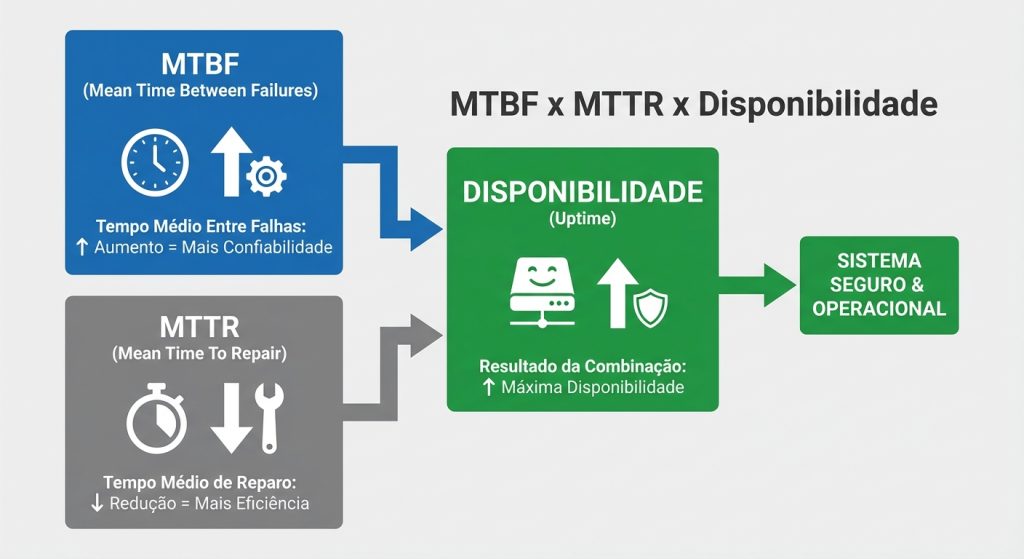
MTBF, MTTR e disponibilidade: o trio que decide a operação
Em projetos de segurança eletrônica para infraestrutura crítica, o objetivo final costuma ser disponibilidade (uptime) com custo previsível. De forma simplificada:
- MTBF (falhas): quanto maior, menos interrupções e menos corretivas.
- MTTR (restauração): quanto menor, menos tempo de indisponibilidade por falha.
- Disponibilidade: melhora quando você aumenta MTBF e/ou reduz MTTR.
Por isso, “comprar equipamento com alto MTBF” é apenas parte da resposta. Se o sistema não tiver observabilidade (alertas de falha), padronização e arquitetura preparada para operação, o MTTR dispara — principalmente em sites remotos e ambientes agressivos.
Por que escolher equipamentos com alto MTBF na segurança eletrônica
Em segurança eletrônica, falhas não são apenas “incômodo”. Elas criam janelas de vulnerabilidade, aumentam custo operacional e geram decisões reativas. Equipamentos com alto MTBF reduzem o ritmo de falhas e ajudam a estabilizar a operação ao longo do ciclo de vida.
Os principais motivos técnicos para priorizar MTBF:
- Menos manutenção corretiva: reduz chamados recorrentes (ex.: câmeras offline, sensores intermitentes, fontes queimadas).
- Menos deslocamento de equipes: em áreas remotas, logística e tempo de acesso podem custar mais do que o componente.
- Menos indisponibilidade e “degradação silenciosa”: falhas parciais (perda de imagem, gravação incompleta) comprometem evidência e operação.
- Menos variação no OPEX: previsibilidade de orçamento e menor dependência de corretivas emergenciais.
- Melhor aderência ao ciclo de vida do site: instalações críticas costumam operar por muitos anos; o sistema de segurança deve acompanhar esse horizonte com planejamento de reposição.
Onde o MTBF “vira dinheiro”: TCO em segurança eletrônica
TCO (Total Cost of Ownership) inclui CAPEX (implantação) e OPEX (operações e manutenção) ao longo do tempo. Em segurança eletrônica, o OPEX cresce quando há falha frequente, diagnóstico lento e reposição difícil.
Os componentes mais sensíveis ao TCO, em geral:
- Câmeras e sensores expostos: ambiente + instalação impactam confiabilidade.
- Infraestrutura de rede/PoE: falhas em switches, conectores e enlaces derrubam zonas inteiras.
- Gravação e VMS: storage degradado e software mal dimensionado geram indisponibilidade “invisível”.
- Energia e proteção: surtos, aterramento e fontes subdimensionadas aumentam falhas e resets.
| Fator | Como aumenta custo | Como MTBF alto ajuda |
|---|---|---|
| Falhas recorrentes | Chamados, reposição, horas técnicas | Menos incidentes por ano |
| Site remoto | Deslocamento, logística, janela de acesso | Menos viagens corretivas |
| Operação 24/7 | Indisponibilidade vira risco | Menos janelas de vulnerabilidade |
| Baixa padronização | Diagnóstico lento, estoque caro | Facilita padronizar linhas confiáveis |
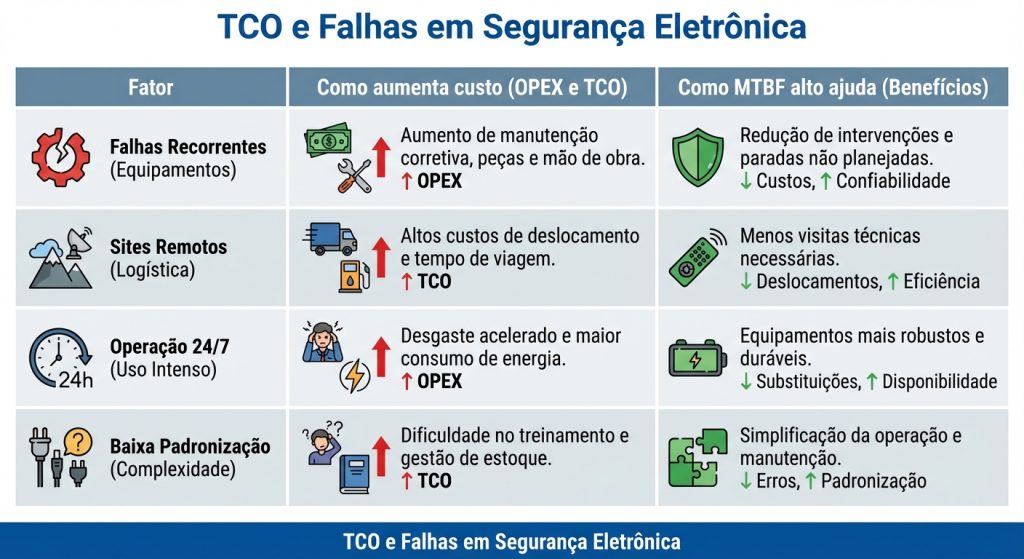
Armadilhas comuns ao comparar MTBF (o que pedir na especificação)
MTBF pode ser apresentado de formas que dificultam comparação entre fabricantes e modelos. Antes de usar o número como critério, valide o contexto.
- Condição de cálculo: temperatura ambiente de referência, perfil de carga, ciclo de trabalho (24/7 vs intermitente).
- Método: MTBF por modelagem (componentes), por teste acelerado ou por dados de campo (cada um tem limitações).
- O que está incluído: apenas “hardware principal” ou também módulos críticos (PoE, fonte, storage, ventilação, conectores)?
- Definição de falha: falha total vs degradação (ex.: perda de frames, queda de bitrate, gravação parcial).
- Derating ambiental: poeira, vibração, corrosão e calor reduzem a confiabilidade real se a instalação não for projetada para o ambiente.
Como transformar MTBF em requisitos de projeto e integração
MTBF alto é mais eficaz quando ele faz parte de uma engenharia de sistema: arquitetura, integração e operação. Em projetos corporativos, isso costuma ser estruturado por projeto e integração.
Um passo a passo prático para “trazer o MTBF para o mundo real”:
- Definir criticidade por zona: quais áreas não podem ficar indisponíveis e qual o impacto de falha por tipo (vídeo, alarme, rede, gravação).
- Selecionar componentes por ambiente: equipamentos e infraestrutura compatíveis com poeira/umidade/UV/corrosão/vibração.
- Reduzir pontos únicos de falha: redundância onde necessário (energia, links, gravação), conforme criticidade.
- Padronizar linhas e firmwares: menos variação reduz diagnóstico, estoque e tempo de reparo.
- Implementar observabilidade: alertas de saúde (câmera offline, storage degradado, link instável, PoE com falha) e relatórios por zona.
- Integrar ao VMS: centralizar evidência e eventos no VMS (Video Management System) para operação e auditoria.
- Definir estratégia de sobressalentes e SLA: peças críticas em estoque mínimo e rotina de reposição para reduzir MTTR.
- Comissionar e medir: baseline de performance e indicadores (falhas por zona, MTTR real, indisponibilidade acumulada).
Comparação técnica: MTBF alto sozinho vs MTBF alto + arquitetura (o que muda)
Do ponto de vista operacional, o ganho não vem apenas do componente “durável”, mas do sistema desenhado para falhar menos e restaurar mais rápido.
| Critério | Foco só em “equipamento com MTBF alto” | MTBF alto + projeto/integração |
|---|---|---|
| Coverage | Depende do que foi instalado | Zoneamento e arquitetura alinhados à criticidade |
| Falsos alarmes / ruído | Pouco endereçado | Regras por zona, calibração e integração por evento |
| Manutenção | Menos falhas, mas ainda com diagnóstico lento | Observabilidade + padronização reduzem MTTR |
| Privacidade | Não é tratado por padrão | Governança e controle de acesso no VMS (auditoria) |
| Escalabilidade | Ad hoc | Arquitetura modular e padronizada |
| Custo operacional | Menor que o pior caso, mas imprevisível | OPEX mais previsível (menos corretivas + MTTR menor) |
Caso relacionado
Para ver um exemplo de implantação em operação crítica com foco em continuidade e confiabilidade, leia o case: UFV Futura.
Perguntas frequentes (FAQ)
1) MTBF é a vida útil do equipamento?
Não. MTBF é o tempo médio entre falhas em itens reparáveis, sob certas condições e suposições. Ele indica frequência esperada de falhas, não “quanto tempo vai durar”.
2) Qual a diferença entre MTBF e MTTF?
MTBF é usado para itens reparáveis (falha → reparo → volta a operar). MTTF é usado para itens não reparáveis (falha → substituição).
3) Por que MTBF é importante em infraestrutura crítica?
Porque falhas geram indisponibilidade, custo de manutenção e janelas de vulnerabilidade. Em operação 24/7, confiabilidade impacta diretamente risco e TCO.
4) MTBF alto elimina manutenção?
Não. Ele reduz a frequência de falhas, mas manutenção preventiva mínima, inspeções e monitoramento de saúde continuam necessários para manter o sistema estável.
5) Como MTTR influencia o custo operacional?
Mesmo com MTBF alto, um MTTR alto (diagnóstico lento, falta de peças, acesso difícil) aumenta indisponibilidade e custo. Observabilidade e estoque de sobressalentes reduzem MTTR.
6) Posso comparar MTBF entre marcas diferentes diretamente?
Com cautela. Métodos e condições de cálculo variam. O ideal é exigir contexto (temperatura, carga, método, definição de falha) e priorizar comparações “mesmo método, mesmo cenário”.
7) O que mais derruba confiabilidade além do equipamento?
Energia sem proteção, rede/PoE instáveis, instalação sem vedação, conectores inadequados, ausência de monitoramento de saúde e falta de padronização.
8) Como o VMS ajuda na confiabilidade?
Um VMS pode centralizar alertas de saúde (câmera offline, gravação degradada, storage) e melhorar diagnóstico e auditoria, reduzindo MTTR.
9) Quais requisitos colocar no RFP para reduzir TCO?
Requisitos de MTBF/MTTR por tipo de componente, condições ambientais, observabilidade (alertas), padronização, documentação as-built, estratégia de sobressalentes e testes de comissionamento.
10) MTBF alto vale para todos os componentes?
É mais crítico para componentes expostos e para pontos únicos de falha (energia, rede, gravação). Em zonas menos críticas, pode haver escolhas diferentes por custo/risco.
11) Como reduzir falhas em ambientes agressivos (poeira/umidade/corrosão)?
Com especificação ambiental adequada (caixas, vedação, conectores), proteção elétrica, instalação correta e manutenção preventiva mínima baseada em condição e criticidade.
12) Por onde começar se meu sistema já falha muito?
Comece por auditoria de falhas por zona (energia, rede, câmeras, gravação), padronize componentes, implemente monitoramento de saúde e reestruture arquitetura via projeto e integração.
Leia também
- Como zerar problemas com altos custos de manutenção de equipamentos de segurança
- HSE em instalações críticas: como a inteligência artificial está transformando essa gestão
- VMS para operação 24/7 em instalações críticas: requisitos técnicos
Conclusão
MTBF é um indicador fundamental para segurança eletrônica em infraestrutura crítica porque ele se conecta diretamente a falhas, indisponibilidade e TCO. Mas o ganho real aparece quando MTBF alto é combinado com arquitetura, padronização, observabilidade e integração com operação (incluindo VMS).
Cada instalação tem ambiente, criticidade e restrições próprias. Uma avaliação técnica do sistema (zonas, pontos únicos de falha, MTTR real e requisitos de operação) ajuda a transformar MTBF em disponibilidade e previsibilidade — normalmente por meio de projeto e integração.
Tags: MTBF, TCO, Segurança Eletrônica, Infraestrutura Crítica